Unplanned Server Downtime Costs for 2019 | The Uptime.com Report
Server Downtime Costs Businesses Without Website Monitoring
This report on server downtime costs attempts to answer three questions:
- What contributes to the overall costs of server downtime for a given industry?
- How expensive is that downtime?
- What factors most influence those costs?
We refer to a Destimate to indicate the cost of downtime throughout this report. This figure is driven by potential risks and threats associated with notable outages we have tracked.
Unplanned downtime can drive significant losses in the form of unrealized revenue. Teams may be caught off guard, or may face an outage outside their control, extending downtime hours unnecessarily.
Without automated monitoring and alerting, teams face undetected outages that silently threaten SLA fulfillment.
The recommendations in this report are best used as a guide on what trends may drive Site Reliability Engineering in the near term.
Server Downtime Data Collected by Uptime.com
Data for this report was collected using Uptime.com’s web monitoring technology to record outages and downtime for 6,378 of the world’s top websites over the period according to Alexa. This Uptime.com Report was built in collaboration with John Arundel of Bitfield Consulting. John is an SRE and DevOps consultant, the author of O’Reilly’s bestselling ‘Cloud Native DevOps with Kubernetes’, and a well-known expert on resilient infrastructure. He blogs at https://bitfieldconsulting.com, tweets at https://twitter.com/bitfield, and is a regular technical contributor to the Uptime.com blog.
It should be noted that the outage and server downtime data applies only to a site’s main landing or login page. An HTTP(S) connection is made to the specified URL, seeking status code 200, at intervals of three minutes and the server performance results are recorded. If the site returns an error status, or does not respond within 40 seconds, the site is considered down and an outage event recorded. We have excluded any websites showing false positive data, such as 0% uptime or extended outages when the URL is publicly available.
One known limitation of our testing is the difficulty of detecting maintenance downtime, but we believe all extended server downtime represents lost opportunity.
We have selected the top websites of each industry to compare to the most popular sites from the 6,378 sites surveyed. Status pages for each industry are available to view below:
We base our Destimate and downtime scoring system on these top websites.
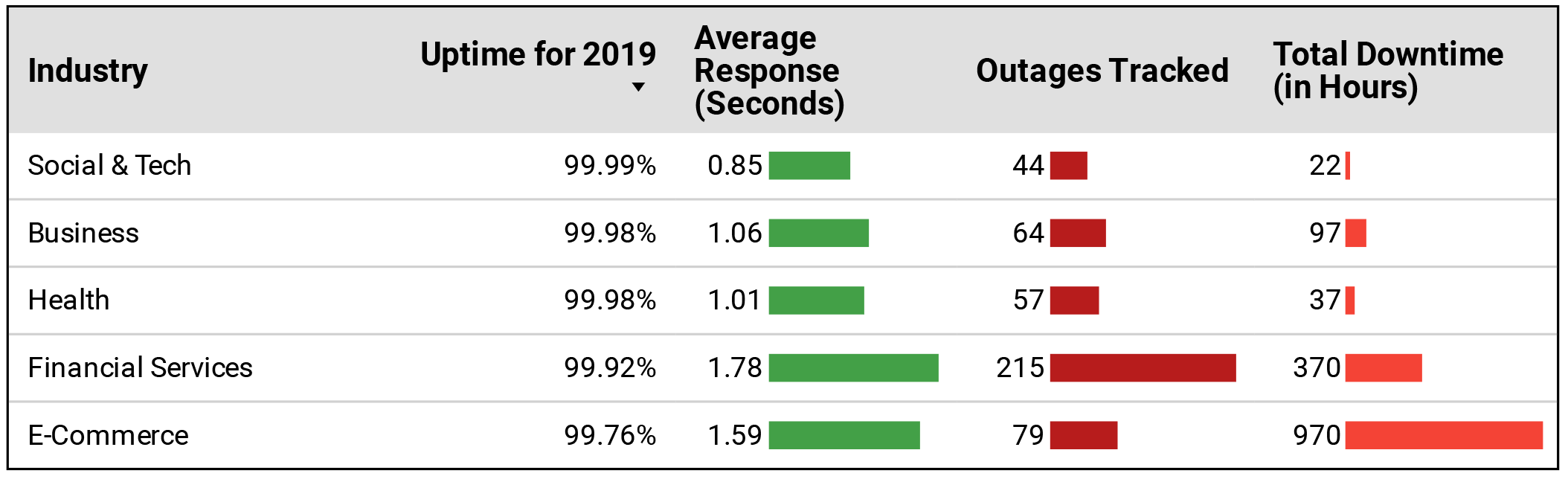
A snapshot of the accumulated data from the top companies and sites in each industry.
What Factors Influence Server Downtime Costs?
What Drags Down Server Performance?
Our data suggests that a high frequency of outages does not correlate necessarily to high downtime hours. We believe that teams better equipped to respond to an outage are more likely to see fewer downtime hours, even when the number of outages is above industry expectations.
DevOps should carefully consider how to escalate downtime events, equip tier I for response, and improve automated web monitoring capabilities for a higher error detection rate. Of the sites surveyed, 35% had fewer than 4 outages with downtime hours less than 10 days. Put another way, 35% of the web’s most popular sites maintain an overall uptime percentage of at or less than 97.3%.
What Causes Unplanned Outages?
Rather than predict the unpredictable, Uptime.com recommends running through several game day scenarios that simulate various ways the system and/or components can go down. Engineers should work as hard breaking the system as they do in building it to ensure infrastructure integrity is sound. Practice redundancy and optimize code for performance to minimize crashes from load.
43% of Alexa top sites we surveyed had downtime less than the average from the top industries.
Are Reliability and Server Performance Related?
A low number of outages does not necessarily equate to the fastest performance. Four of five industries tracked had fewer than 100 outages, but three of those four saw average performance higher than one second.
Teams should consider performance as an indicator of potential problems, and we believe that performance and outages are linked. DevOps should aim for a balance between speed and uptime, where new upgrades take impact on existing infrastructure into account.
This is also a lesson in chasing perfection, where investment in resilience and performance may become prohibitively expensive. An audit of incident response and implementing incident management best practices to keep response time as low as possible can ease the demand for additional bandwidth to deal with surges.
What Prolongs Server Downtime?
There are two factors contributing heavily to downtime hours: scope of the outage and time to respond. If a data center is on fire, the outage will last until redundancy can kick in. But teams can and should drill and work toward consistent improvement in time to respond.
Additionally, monitoring for multiple factors (such as performance and/or high traffic volume) can provide early warning indicators of imminent infrastructure failure. DevOps must consider clever ways to monitor a system for unforeseen and undetected outages.
Destimate Explained | Cost Benefit Analysis of Server Downtime
What is a ‘Destimate’, and how is it calculated? SRE consultant John Arundel explains:
“Downtime is bad, but how bad? It makes business sense to spend money and effort on avoiding it, but how much? A powerful way to help you make these decisions is to assign a dollar value to every minute of downtime—what we’re calling the ‘destimate’ (we hope this term will catch on; try to mention it in conversation).
Of course, this exact figure will vary widely depending on what your business does and how it does it. But if you’re online, and if you’re reading this, that seems a safe assumption, server downtime costs you something. If you make a billion dollars a year from your online service, and it’s down 1% of the time, we may estimate the cost of that as, very roughly, 1% of your revenue. Ten million dollars here, ten million dollars there, and pretty soon you’re talking real money.
Of course, for some businesses, online services are more critical than for others, and it’s not just about lost revenue, it’s about the effect on your brand, your reputation, and your stock price. Also, a loss of ten million dollars might be overlooked on some balance sheets, but would put other companies out of business fifty times over. So to make Destimate figures comparable, it’s useful to express them as percentages, rather than dollars. X% downtime costs you Y% of revenue.
What is the exact Destimate figure for your company or service? You’re in a much better position to say than we are. But you can look at the industry figures we’ve provided and decide for yourself if downtime is more or less expensive for you than these benchmarks. And if it costs you ten dollars a month to avoid a hundred dollars of downtime, that begins to sound like good business, doesn’t it?”
The Uptime.com Destimate for 2020 takes the following factors into account:
DDoS a High Destimate Risk | Web Monitoring and Mitigation Recommended
What makes DDoS attacks so costly to business? Consultant John Arundel explains.
DDoS attacks are probably the most dangerous threat that any business faces to its web presence. One reason for that is that they are cheap to make and difficult to mitigate. The controllers of botnets usually rent them out to the people who want to make the DDoS attack. The cost varies, but for around $20, it’s possible to launch an hour-long attack with a network of perhaps several hundred machines, easily enough to take down the average unprotected website.
DDoS attacks cause prolonged website downtime, connectivity issues, and intermittent outages that are regional in nature and difficult to monitor for. The aim is to bring a site down regionally, and globally if possible.
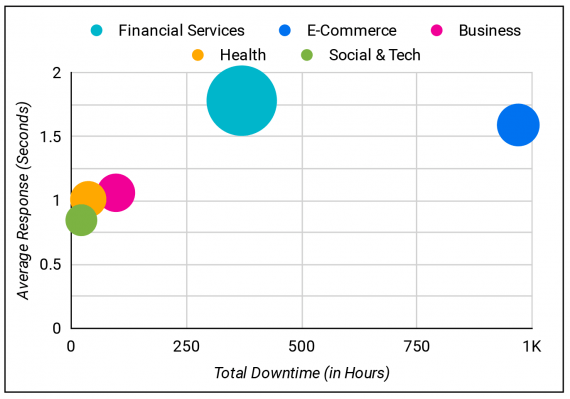
Industries with higher numbers of outages tended to have a higher average response time.
No tier is immune to DDoS, and in fact attacks can grow in scale alongside their targets. A wider customer-base presents a larger target, and attackers may find large and mid-sized businesses ideal targets for these reasons. The level of traffic generated by a big DDoS attack can be so enormous that the infrastructure required to handle it becomes prohibitively expensive. So long as it’s cheaper to run the attack than to defend against it, the attackers have the advantage.
Solutions
Uptime.com recommends a DDoS mitigation provider to automatically detect attacks and route traffic away from your infrastructure. Continuous monitoring of various user portals and load balance is essential to maintaining connectivity. Uptime.com further recommends checks aimed at each DNS server used in the balancing algorithm for the most accurate picture of infrastructure status.
Alerts and escalations are a requirement as DDoS attacks strike hard and are intended to overwhelm. IT should have escalations in place for parts of infrastructure most vulnerable to DDoS attacks.
Customer-Facing Transparency Can Improve Server Downtime Destimate Risks
Finance and banking businesses are changing constantly, in part to adapt to improving security standards and to compete in an increasingly technology-oriented world. This industry must allow for some downtime, but would benefit from more transparency regarding outages.

The Financial Services Industry had the most outages.
Our data shows that this industry suffered the highest number of outages, the highest downtime hours by volume, and had the second lowest overall uptime percentage.
This problem is one of customer service. When the end user can’t access money, a small problem becomes a crisis. We observed this in several financial players, where outages extended and the end user was left with no recourse. In some cases, an initial outage became a rolling series of incidents in which hasty attempts to fix the problem ended up making things far worse. Intense pressure to minimise the amount of downtime can actually increase it.
Solutions
Banks are especially sensitive to customers’ confidence in their services. Uptime.com therefore recommends financial businesses adopt an approach to incident management that includes user transparency.
Customer service and Devops should be in sync on outages, investigation status, and updates regarding service restoration. A failure in communication can cost heavily in the form of negative PR and users abandoning the service. Outages large enough can result in legal action.
Unplanned Server Downtime Carries a High Destimate Cost| Improve Observability
Outages happen, but Devops benefits from knowing about them before the end user. As we’ve seen with financial organizations, the customer component is a major factor in incident management.
Any outage the company learns about through a support ticket eats customer support resources, may include customer recompense, and degrades trust in the service. Certain conditions are also difficult to track as infrastructure grows in complexity. You may require internal and external monitoring for multiple points of infrastructure.
Customers aren’t delighted if you have outages, but it’s not necessarily a deal-breaker. What really counts is time to resolution. No one can avoid outages altogether, but what separates the top-tier companies from the rest is how quickly they detect and resolve issues when they do happen.
Solutions
There are two components to this: monitoring and observability. They sound like the same thing, but they’re not. Monitoring tells you when your system is down; observability tells you why it’s down.
For example, suppose that as part of your monitoring, you make automated requests to your website using an Uptime.com transaction check. The simulated customer goes to your home page, logs in as a user, does a search for a product, adds the product to the shopping cart, goes to the checkout page, enters credit card details, and makes the purchase. If any part of this process fails, you will be alerted right away that something is wrong. But what?
Now let’s suppose that, to improve your observability, you also monitor your various internal services and endpoints using Private Location Monitoring, for example. Because your private Uptime.com monitoring server runs within your own environment, it can have secure access to APIs and services that customers (and external monitoring checks) can’t see.
Does this internal monitoring shed any light on the outage? Checking your email, you see an alert for an internal service called `process-payments`. This is the part that authorizes the customer’s payment with the card provider. It looks like the card provider’s service had a momentary glitch that stopped your simulated customer’s purchase from being completed.
This is really valuable information, because now you don’t need to have engineers spend hours checking over the system to work out where the failure might have occurred. You already know, and you can communicate this to the support department, so that if any real customers were affected, they can get a prompt and helpful explanation of what went wrong.
Time to resolution: just as long as it took you to read an email. Combining both internal and external monitoring with observability metrics is part of how industry leaders minimize their downtime, and maximize their business.
We tend to take infrastructure for granted. When it works, no one thinks about it. When it goes down, everyone starts talking about what went wrong and how to fix it. With game day exercises, DevOps essentially runs “practice” for resilience and team response. A good game day exercise breaks something, causes a response and leads to an improvement in the system.
Providers Fail and Affect Services | High Destimate Risk
Some of the biggest infrastructure providers suffered extended downtime in 2019, and the outages affected even backup systems. Businesses reliant on the internet to charge credit cards, run scheduling, and provide general services were completely stalled.
Teams can respond impeccably yet remain reliant on changes in infrastructure outside their control.
These problems can range from small social media outages that affect outreach, to major incidents that bring down content distribution networks entirely. Businesses unable to serve content to the end user lose opportunity.
Solutions
Redundancy is probably already a part of building out your applications, but DevOps needs to consider geographic redundancy. Spreading connectivity across data centers is advised, so an outage in one region doesn’t bring everything down.
Techniques like “BLOB” storage can also help. Binary Large Objects can be segmented to other databases, which mitigates the scale and scope of outages.
There’s a saying in the US Navy SEALs, and other such results-focused organizations, that “Two is one, and one is none.” In other words, unless you plan for failure, you’ve failed to plan.
Where the best-laid DevOps plans often fall down is in the last 10,000 miles, so to speak. When the ones and zeroes leave your server or cloud service, they have to travel through some physical switches and fibres—planet-spanning fibres—to get to the customer. There’s a lot that can go wrong here, from someone unplugging the wrong outlet, to undersea cables being attacked by sharks (yes, sharks. Shark-induced network outages are a thing.)
Without laying your own undersea cables, how can you get a measure of redundancy at the service provider level? Well, a good place to start is using multiple service providers. If it’s possible or economic to duplicate your services across two different clouds, for example, that’s worth doing.
Geographic redundancy helps too. A dinosaur-killer asteroid might take out a cluster of data centers in a single city (and maybe internet outages will be the least of our problems in that scenario), but it’s unlikely to affect two different continents. If your users are worldwide, your services should be too, and users will also get better performance from a local Point Of Presence (POP).
Internet service providers probably aren’t the only critical dependency you have; what about DNS services, payment processors, email handlers, and the JavaScript libraries that make your web pages work? What happens if any of them are unavailable? If you deploy your code from a third-party code hosting service such as GitHub, what happens if GitHub is unavailable?
There can be a lot of engineering required to make all your services truly redundant, and maybe you’re not in a position to do all of it yet. That’s okay. We understand. But you can start thinking about it. And any engineering decisions you do make should take into account that some day, at some point, you’re going to need to add redundancy. Don’t close off that door without good cause; one day, it may be your emergency exit.
Conclusions
In 2019, the Uptime.com Destimate is that businesses lost an average of between 6% and 11% of online revenue across industries, with some industries (such as eCommerce) seeing a higher Destimate risk. It’s important to note that the Destimate is based on the top players in each industry, which have some of the most reliable websites in the world. 57% of the sites we surveyed, though, fared worse than the industry leaders…
We estimate businesses can expect to lose significant revenue from downtime in 2020, with those $1 billion in revenue with an average of 15% from online sales seeing major losses:

We find that this risk is compounded for smaller companies as they grow in scale. There are multiple reasons for this, the primary ones being that a growing company presents a more profitable target for hackers because they are less likely to detect something has gone wrong.
These findings underscore the need to invest in IT infrastructure, personnel, outside capabilities and automated monitoring to support scaling architecture. The costs are in addition to inevitable downtime events, such as outside providers failing, which may or may not factor into a company’s service level agreement.
The majority of top Alexa sites surveyed did not meet industry expectations for uptime as a percentage and number of outages; either teams do not adequately respond to outages or the problem is a lack of redundancy. The top businesses we surveyed tended to practice rapid incident response and active monitoring. In some cases, outages were restored by the time reports were reaching social media.
Destimate Auditing
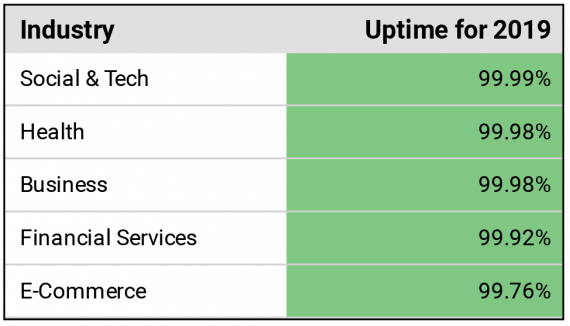
We recommend businesses find their own Destimate, or a figure corresponding to the cost of downtime equivalent to the percentage of downtime for the year. There are two methods we suggest to score your business when auditing for downtime:
- Uptime for the year against our industry figures
- Destimate cost
Using these two methodologies will provide a sound indicator of potential losses due to downtime, and can be used as a guide when considering further investment in IT infrastructure.
Uptime.com provides reliable SLI services and SLA reporting in fulfillment of your monitoring end goals. Our network is built with resilience and uptime as our primary focus. Continuous upgrades, the most integrations, and best-in-class support ensure Uptime.com remains a leader in downtime monitoring.
Minute-by-minute Uptime checks.
Start your 14-day free trial with no credit card required at Uptime.com.


