
Got Game? Uptime.com Secrets of Great Incident Management
When his phone wakes him at two in the morning, operations engineer Andy Pearson knows it’s bad news. There’s a major server problem, and hundreds of client websites are down. Automated monitoring checks detected the outage within seconds, and paged the on-call engineer. This time, it’s Pearson in the hot seat.
Pearson quickly confirms the issue is real and, escalates it to his boss, tech lead Lewis Carey. Within five minutes, Carey has assessed the situation and declared a major incident. A well-rehearsed procedure goes into effect. A conference call begins; the sleep-fuddled incident response team assembles as Carey assigns roles to each of them.
The next sixteen minutes are going to get intense.
Table of Contents
Incident Management Roles
Carey is the Incident Commander, taking overall responsibility for the process. As DevOps consultant and SRE expert John Arundel notes, “The key thing is to have one person in charge. Downtime is not a democracy. You need a decision maker. Often, this will be the team lead, but over time, you should make sure to give everybody a turn in that chair. One day, the team lead won’t be around, and anyone should be able and confident enough to run an incident.”
Pearson is the Driver, operating the keyboard and sharing his screen with the team. Developer Juan Kennaugh is the Communicator, in charge of giving status updates to affected clients, project managers, and management.

An example of an Uptime.com status page showing the various stages of an incident.
A key role in the team is Records, who documents everything as it happens, taking detailed notes, capturing screenshots and log entries for later analysis, recording what the team discussed, the things they tried, the results, and the decisions they came to. All of this raw data will later go into a detailed post-incident review, but for now, things are unfolding so rapidly that the designated Records keeper, Elliott Evans, is struggling to record them.
Meanwhile, systems expert Rich Rawlings is assigned to the Researcher role. As questions come up in the troubleshooting process, Rawlings is kept busy hunting down the answers.
Drilling the Fundamentals of Incident Management
The first thing the team does is run an in-house snapshot tool, created by Rawlings, which captures all the key log files and status information from the ailing machine. “In case the server goes offline altogether, we need to save everything now,” Rawlings explains. “It’s like an aircraft’s black box recorder. When we analyse this data we may find important clues about what went wrong.”
It’s like the movie ‘Apollo 13’. We don’t want to make things worse by guessing. Instead, we work the problem, step by step.
The team looks at the results and starts running through a troubleshooting checklist, item by item. “Right now we’re just identifying where the problem is,” says Carey. “Is it in our domain—servers, configuration, code? Or is it a third-party outage—networking, cloud hosting, DNS?” It’s looking as though the problem is network-related. Even as Pearson types into a console window, the text stutters and stumbles, seeming to hang for a few seconds and then catch up.
The team deliberately takes a few extra minutes to verify the suspicion of a network problem. “It’s like the movie ‘Apollo 13′”, Carey explains. “We don’t want to make things worse by guessing. Instead, we work the problem, step by step.” In a high-pressure situation like an outage affecting hundreds of clients, there’s a strong predisposition for action. But the wrong action can be worse than no action at all. “What we don’t want to do is jump the gun and do something that we can’t recover from. If this were a security incident, for example, this server could technically be a crime scene.” The team, under Carey’s leadership, moves with forensic precision.
“Okay, we’re 95% sure this is network,” Carey observes to the team. “I’m going to suggest we open a support case with the ISP to get that fixed, and in parallel, let’s kick off an automated build for a new server, so we can migrate all the failed sites to it. Everyone happy with that?”
Decision made, the team acts swiftly. Communications chief Kennaugh updates the company’s management on progress, and alerts the social media and support teams with the latest ETA on a resolution. “We’re aiming to have everything back in 15 minutes, one way or the other. If the ISP can fix the network in that time, great, but we won’t be sitting around waiting for them: we’re already building a replacement server,” says Kennaugh.
Meanwhile, Evans is contacting the ISP’s support department, Pearson is spinning up a new cloud server, and Rawlings checks the documentation and procedures for migrating websites, getting everything ready to run so that not even a second is wasted. “You can’t eliminate downtime completely,” says Pearson, “but what you can do is make the troubleshooting and resolution as fast as possible. You automate everything that can be automated, and for the parts that can’t, you build a procedure that takes the guesswork out of the process.” The team drills on these procedures regularly, so that when the alert goes off, everybody knows what to do and when to do it.
Within eight minutes—well within the team’s self-imposed deadline—lights are starting to go green on the team’s uptime monitoring dashboards. One by one, sites are being automatically migrated to the new server, and coming back to life. “Every one of the hundreds of sites we operate has an auto-generated monitoring check,” explains Carey. “Each check verifies, minute by minute, that the site is up, the DNS is correct, the SSL certificates are valid, that clients can log in, and if any of those things stop working, we get alerts within a few seconds.”
Automated monitoring also records performance and uptime for all sites, which is reported back to clients, along with aggregated data that the firm’s SREs review constantly to check that all is well with the infrastructure.
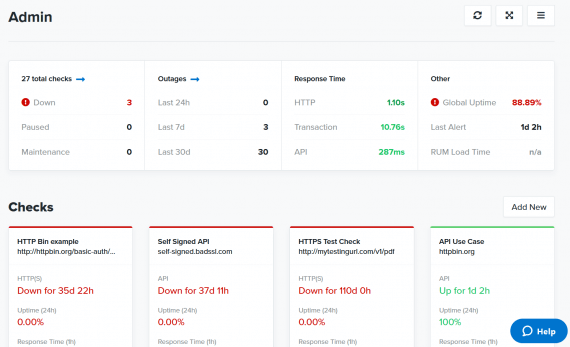
Customizable dashboards give SREs immediate access to relevant statistics for incident management. What’s Up, what’s Down. Find out with Uptime.com.
As the last red light changes back to green, Carey starts to wrap up the incident. “Okay, Comms, can you let everybody know we’re back up? Records, do you have everything saved? Driver, Research, have we captured all the post-incident actions for later? Great. Good job, everybody. Incident closed at… 2.16. Back to bed and I’ll see you in the morning.”
But this is no time to go back to bed. In fact, it’s mid-afternoon. And there’s been no downtime; no client sites ever glitched out, even for a moment. For the tech team at leading UK digital agency ThirtyThree, this has all been just another exercise.
“We call it ‘Game Day’,” explains Carey. “It’s basically an incident management drill, but we do everything exactly as we would for real. The monitoring is real, the alerts are real, the actions are real. Only the problem is fake.”
“It’s a lot of pressure,” Pearson comments afterwards. “Everybody’s looking at you, there’s a lot of noise and confusion, a dozen things happening at once… really simple things suddenly become a challenge. That’s why we practise all the time; so it becomes second nature.” In the heat of incident management, with hundreds of clients and potentially millions in revenue at stake, and all attention focused on them, Carey’s well-drilled team hasn’t missed a beat.
Red vs Blue: Incident Management Teams on Their Process
Each developer takes their turn on the Red Team, designing and executing a realistic outage scenario, which isn’t revealed to the others until after the incident is over. “You never know what it’s going to be,” says Evans. “Last week it was a jammed-up database. Another time it was a DNS poisoning attack. We have to be ready for anything.” The team has even handled a full-blown security incident, where simulated malware was uploaded to a specially quarantined server.
For this exercise, the ‘Red Team’—played by Rawlings—has simulated a networking issue, by deliberately injecting extra latency into the server’s network stack. As packets are randomly dropped or timed out, it plays havoc with connections to the machine, triggering the automatic site monitoring to raise the alarm, and begin the simulated incident.
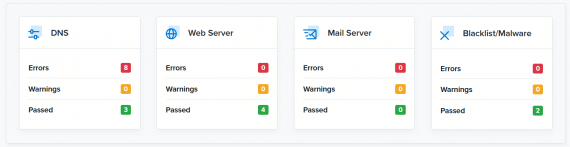
Use the Domain Health Check Tool for a spot check of services. Confirm your internal findings with a quick external test.
“Game day exercises are incredibly valuable,” Carey explains. “First, it brings everybody together as a team. When you’ve been through the fire of a major incident with someone, you develop new respect for them. Second, we’re learning new things every time we do this. We have a detailed debrief afterwards where we look at what worked, what didn’t work, and what we could do better next time.”
Often the team learns lessons which can help prevent real downtime. As Arundel explains, game day exercises are a way to test your systems and procedures in a safe environment. “It’s like testing to destruction, only without the destruction. You can screw up, and no one dies. But when you screw up, you can figure out what you did wrong, and do better next time. Oh, the procedure says dump the database, but if you do that, it actually crashes? Great. We can fix the procedure, or figure out another way to dump the database. Good thing we found that out before it happened during a real incident.”
Simulated downtime saves real downtime. “Figuring out game day scenarios is useful in itself,” points out Pearson. “We look at the system and say, okay, what happens if this breaks? What could we do about it? Sometimes the answer is, it turns out we really couldn’t fix this quickly enough during an incident. So instead, we do some engineering ahead of time to make sure it doesn’t happen, or design a procedure for getting to a faster resolution. Every game day we run now prevents a dozen real incidents in the future.”
Overcoming the Pressure of Incident Management
Game days give ThirtyThree a genuine edge in a crowded marketplace. “It’s not just the technical stuff,” says Carey. “Cutting-edge infrastructure is no good without the right people to run it. We’re constantly training ourselves to work together as a team, to think on our feet, to lead, to make decisions, and to communicate well under pressure. Game day is a big part of that.”
The more reliable your systems, the less frequently real incidents happen, so the more you need to practice them. “Sometimes months can go by without serious issues, so when they actually happen, nobody remembers what to do,” says Arundel, who works with many of his consulting clients to help organise realistic game day exercises.
“Automation is a fantastic thing, but the more automation you have, the less you need to know about how the system works, down among the details.” Airline pilots know this, and even though modern aircraft can essentially fly themselves, the pilots still make regular manual landings and take-offs, and practice emergency procedures in the simulator. “This is the best way to keep your skills sharp and your knowledge up to date.”
Planning Your Incident Management Game Day
Arundel, Uptime.com’s inhouse SRE expert, has some tips for those planning their first game day. “Keep it short and simple the first time round. Put together a basic plan for what you’re going to do: this is the first draft of your incident handling procedure.” If you already have such a procedure, this may be the first time you’ve ever actually run it as a team.
As the team gets more practiced, assign roles to other members, like Communicator, Driver, and Researcher. “For long incidents, you’ll need to rotate these roles every hour or two, so that people can take breaks, and you can get a fresh pair of eyes. But for your first incident, an hour is plenty. In fact, plan to give the team the rest of the day off. Do the debrief the next morning, when the adrenalin has burned off and everybody’s had time to reflect.”
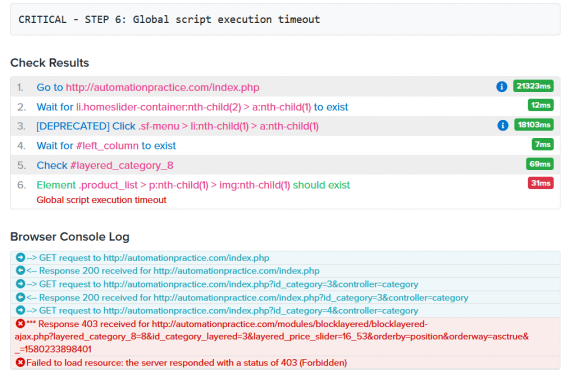
Accurate alert details are critical to root cause analysis. Use Uptime.com tools such as the browser log to get a deeper glimpse into the actions a probe server takes and how the server responds.
It’s hard to convey how stressful an incident is until you’re in one, and even a game day simulation puts real pressure on everybody. In some ways, this is the true value of the game day exercise. “Once you’ve done a few game days, it’s all a lot easier,” says Carey. “The last thing any team needs in a crisis is extra stress. We get all our stressing out of the way beforehand, so when the real incident happens, we can calmly focus on doing what we need to do.”
If you’re not already running regular incident management exercises with your team, maybe it’s time to start. Or the next time your phone sounds at 2am, it could be for real.
ThirtyThree is a full-service digital agency, specialising in areas ranging from recruitment advertising, graduate communication and digital marketing to social media strategy, market research and employer branding. With offices in London, Bristol and New York, they’re transforming the way organisations attract, recruit and retain talent, using technology, insight and award-winning creativity. You can contact them at hello@thirtythree.co.uk.
Minute-by-minute Uptime checks.
Start your 14-day free trial with no credit card required at Uptime.com.


