
How to Improve Downtime Response: Error Budgeting and Unplanned Downtime
Every one of us reading this blog has seen a fire spring up and quietly walked away from the impending chaos. And everyone one of us has managed to live this long because we understand when to react to a fire.

A real fire affects our Service Level Objectives (SLO), and affects the user base. You need to figure out where it is, what started it, and what your team will do about it, and you need to do that now. Then you need to examine how you responded to see whether any holes or roadblocks impede your progress.
What are the key factors that have to align to get you out of bed with alarms and whistles? What wakes you up?
We know incidents don’t conform to our schedule, and that not every fire is worth bringing in the cavalry. So today, we’re going to ask ourselves if this is really worth getting out of bed for. How do we not only prioritize alerts, but improve our response time?
Error Budgeting Your Bedtime
Vince Lombardi said “Perfection is not attainable, but if we chase perfection we can catch excellence.” SLOs built on unrealistic fulfillment are the first recipe we have for disaster. You are guaranteed to overpromise and under-deliver to a dwindling audience over time.
How to Error Budget
Good SLOs use something called an “error budget” to ensure a manageable user experience. Secondarily, good SLOs make sure that the devops team isn’t quietly plotting to burn the place down when no one’s looking.

Error budgeting is another way of referring to the amount of unplanned downtime your organization deems acceptable. Here’s a table from Google that provides figures for the math behind the nines, but you want as many nines as you can conceivably handle. Budgets will differ based on team and infrastructure size. One person managing an app with hundreds of users has very different concerns than a team managing a service with hundreds of thousands logged in concurrently.
But error budgets serve another important function: they define when to stop what you’re doing and fix something. An SLO may or may not be legally binding, but it does provide a framework for how to treat systems under stress.
Simply put: you can continue deployments under ABC conditions, but stop everything for analysis and reliability work under XYZ conditions.
The best SLOs are extremely specific about when and how the team needs to react to unplanned downtime. If the error budget is consumed too quickly, the team must be able to explain what happened and create an incident report that details what went wrong. That report will help further define your escalation policies.
Defining an Escalation Policy
So, then, the question becomes: what is unplanned downtime? Simple answer: anything not within your control that triggers downtime. But when we think about SLOs, the answer gets a bit muddled. Let’s say we have a website that is OK 200, with a support chat function that is closer to :sadface: 400. Does that down chat factor into our SLO?
Is it worth getting out of bed for?
Yes, we should know it’s down and we should have a plan to fix it. Do we need to act on that at 3 AM when we first receive the alert it’s dead? Probably not.
So, part of error budgeting involves wasting less time figuring out whether the fire is a big one. When we know more about which systems affect the customer experience, we can waste less time deciding whether an alert is worth acting on.
You can take this a step further. Finding yourself getting out of bed just to reboot a service? Automate it! Recurring errors giving you the blues? Tell tier 1 how to fix them while you sleep so you can feel refreshed enough to do the root cause analysis tomorrow and figure out how to stop them.
All of these methods help improve downtime response without excessive costs to your error budget.
Two Steps to Beating Your Error Budget
There are two steps you can take to improve your downtime response and ultimately beat the numbers you’ve set as your error budget.
Collect Data on Uptime and Performance
The first is to start collecting performance data now. Here’s a handy link to create a RUM check if you’ve not already done so. Use this performance indicator as your first line of defense, because the user experience is why we all show up in the morning.
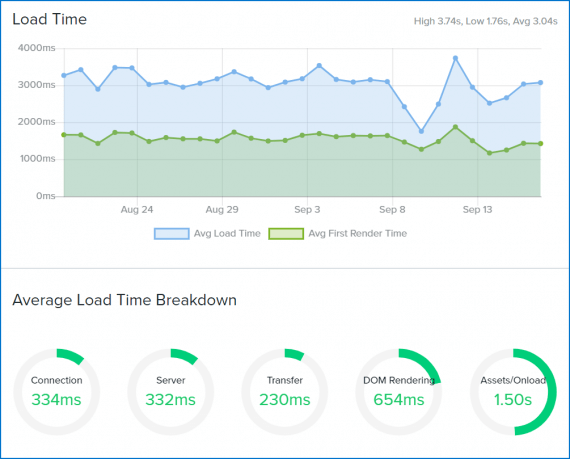
Real User Monitoring tells us how our website is performing, and it’s powered by real user data. When you review a RUM report you step into the user’s shoes for a clear picture of how they perceive the website. It’s also got a built-in threshold for performance, alerting you when the load time exceeds the value you define.
Performance checks like RUM are the sensors on our star cruiser, diligently informing us of the dangers ahead.
The more performance thresholds you can identify as meaningful, the more data you have for first response. You know when it’s slow, when slowness becomes downtime, and the severity and length of that downtime.
Escalate Unplanned Downtime
The second step we can take to improve downtime response is to practice meaningful escalations.
The kind of downtime you’ve experienced is crucial in determining what you do with your alerting. If we circle back to our RUM check, our defined threshold helps determine when it’s time to examine the problem. Until that threshold is met, it’s nice to know performance is fast or slower but service levels must have an acceptable operating range. No need to blow the horn just yet.
If our RUM check triggers an alert, and some of our HTTP(S) checks go down, we might need to get out of bed.
We can think of escalation in terms of when and where. When should we escalate to the next tier, and where will our message have the greatest impact. First, let’s tackle the “where” portion of escalations.
Where is easy: wherever your team lives. Do you live on Slack? Are you all married to some other provider? Do you exist on mobile, or have internal dashboards and ticketing? Where is easy to define when we think about how your team works.
Now let’s think about “why”, which is the really interesting part.
Modern applications are full of complex and interlocking systems, with redundancy built into everything we do. If one server from a farm of 10,000 goes down, is it really worth getting out of bed for?
You would know if you had more clarity on which one went down.
An alert that has no actionable takeaway isn’t very useful. You’ve just been roused out of sleep to learn that you shouldn’t or can’t actually do anything. Alerts like these are over before you see them, or they have little to no impact on the end-user.
On the other hand, too many alerts will drive anyone to levels of insanity that create DevOps horror stories that make the front page of Reddit.

Photo by Lewis Parsons on Unsplash
Why we escalate becomes a question of the cost of downtime to your organization. We looked at some hypothetical downtime costs during Black Friday 2019, if you’re interested to see what these calculations might take into account.
Simply put: what’s the end-user cost to something going down? Is there potential for a bounce or a lost sale? If so, how apocalyptic is that threat?
Here are some quick guidelines you can use to assist in escalating:
- Would this outage prevent the end-user from accessing a critical portion of the application?
- Would this outage affect the end-user performance?
- Can a human intervene with a meaningful action?
- When does an alert become “urgent” for your organization?
Auditing for Ineffective Alerts
When alerts overload us, we miss the important ones. Just like you have an error budget, you also have an alert budget, or a measure of how many alerts you can send before they all just look like a blur. The alert budget is measured in staff size, on-call hours, and resources generally available to you.
Measure the number of alerts your team is receiving in a given period (say monthly or weekly), then look at how many had an immediate action taken. The escalations you don’t need were ones that failed to produce an action item without further analysis conducted during normal business hours.
If you follow our advice above and collect performance and user data continuously, you’ll have a better gauge of how your systems affect one another and what the user is seeing.
Error Budgeting the User Experience
A more perfect internet is one where we all experience near-zero lag and permanent connectivity. We’re kind of a long way away from that dream, so really error budgeting is about protecting the user experience as best we can.
There’s a balance between meaningful, actionable alerts, sane DevOps, and the user. Your job is to manage that balance.
With Uptime.com, you have a few options. You can set escalations in bulk, allowing you to target entire systems in a single click. You can also add notes and pull metrics and alert data to package as you need.
We also have the most integrations in our class, with status pages that can be public or private to your organization. We give you the visibility you need, high level or granular, delivered direct to you.
Error budgeting, visibility, and alert budgeting are all related concepts. Less noise, actionable alerting and better on-call utilization are all good end goals. Your employees and users will appreciate a stable experience.
Minute-by-minute Uptime checks.
Start your 14-day free trial with no credit card required at Uptime.com.


