
Key Availability and Uptime Metrics, Stats, and KPIs You Should Monitor and Report On
What are availability and uptime metrics and why should you measure them? In the past, development teams pushed new features, and operations teams handled issues as they arose. However, as more businesses pivot to a DevOps infrastructure, all IT teams work side bcy side throughout an application’s lifecycle, from coding and testing to deployment and monitoring.
As these information silos break down, there’s an increasing sense of shared responsibility between software developers, IT operations, site reliability engineers, and other stakeholders, with metrics serving as the common language that helps all parties align.
This guide will teach you the most important availability and uptime metrics, explain why these key performance indicators (KPIs) matter, and clarify how you and your team can use reporting as a tool that keeps your online assets competitive.
What Is Uptime?
A service’s overall reliability depends on its uptime stats, which measure how often a server is fully operational over a specific period, typically a year.
While this number will never be 100%, it should be as close as possible. Even a seemingly nominal drop in percentage translates to significantly more downtime in a year.
- 99.9% uptime = 8 hours of downtime annually
- 99.99% uptime = 52 minutes of downtime annually
- 99.999% uptime = 5 minutes of downtime annually
Uptime KPI Formula
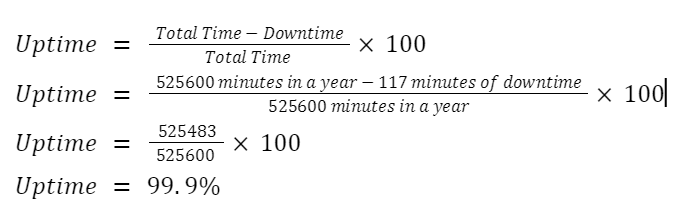
Calculating Downtime From Uptime
As the inverse of uptime, downtime accounts for that small percentage of time when a server is unavailable during the same period for which uptime is calculated.
Referring to our previous example, 99.99% uptime statistics would put the downtime at 0.01%.
Downtime KPI Formula
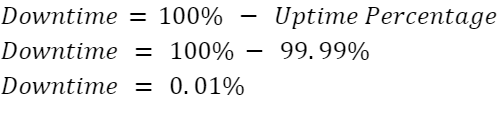
What Is Availability?
Availability refers to the percentage of time a service or system is accessible and working as expected. It’s more informative than uptime because it only includes times when you provide an uninterrupted, fast, error-free experience.
Consider a website with an uptime of 99.9% in a month, meaning it was only “down” for around 45 minutes. However, if those users couldn’t log in to their accounts for 5 hours that month, then the availability drops to 99.21, which accounts for both the 45 minutes of planned downtime and the 5 hours of compromised functionality.
Improving your service availability metrics requires analyzing more granular data to identify opportunities to streamline the processes that contribute to downtime. Mean time to detect (MTTD), mean time to repair (MTTR), and mean time between failures (MTBF) data zoom in on the specific stages of incident management and can help teams prioritize solutions.
Availability Metrics Formula #1
The first option for calculating system availability metrics requires using the uptime statistics and plugging them into a formula that directly accounts for planned and unplanned downtime.
For example, in one year, you have 8.5 hours of scheduled maintenance and updates and an additional 2.25 hours of unexpected downtime.
Example:

This straightforward formula gives you a percentage based on the time the system is up versus down, so it’s great for getting a quick snapshot of availability. However, it doesn’t detail why downtime happens or how to improve it.
Availability Metrics Formula #2
Alternatively, you can use the MMTF and MTTR variables. Unlike the previous formula, which uses only raw application uptime metrics, this formula lets you compare the relationship between failure frequency and recovery time.
You can then use it to determine where to focus improvements — increasing stability or improving response times — and more accurately predict future availability for service level agreements (SLAs).
Example:
There’s a service failure every 100 hours (MTBF), and it takes 45 minutes to recover (MTTR):

API Availability Metrics
Just like with overall system availability, it is important to monitor your application programming interface (API), and it should be available as close to 100% of the time as possible, whether they’re yours or a third party.
Even if you keep your APIs in perfect working order, third-party API downtime can still drag your service down with it. Be familiar with the third party’s SLA so you can plan for service interruptions and know the guidelines for what to do if those thresholds aren’t abided by.
Web and Network Performance Metrics
Uptime metrics tell you how often your services are online, but that’s only part of the story. A service that’s technically “up” can still leave users frustrated if the interactions feel sluggish, so your teams will also want to stay on top of the following web performance KPIs.
Response Time
Once a server receives the client-end request, time starts ticking to determine how long the client’s system takes to get that data back.
However, response time is often divided into more specific real user monitoring sub-metrics so your team can better identify performance bottlenecks, such as network latency.
First Contentful Paint (FCP)
The FCP is the time it takes for the first piece of meaningful content, such as a header, hero image, text, etc., to appear on the user’s screen. Google recommends keeping the FCP under 2 seconds to keep users satisfied.
Total Blocking Time (TBT)
After the FCP, the page will visually load in its entirety but will still be unresponsive to input. A high TBT typically means the browser must work harder to process the JavaScript or parse CSS. Optimizing script execution can help bring that number below the recommended 200 milliseconds.
Time to Interactive (TTI)
It’s one thing for a page to appear quickly, but another for it to be ready for the users to interact with. That’s why one of the uptime metrics worth monitoring is how long it takes for a page to become entirely usable.
The faster the TTI, the faster users can click, scroll, and type without being held up by scripts or processes still loading in the background.
Page Speed
Page speed is the cumulative time it takes for the browser to fully load and make a web page usable, starting from the moment of the initial request until all content is visible and scripts are executed.
Users expect pages to load in around 3 seconds, but the faster you are, the less likely they are to bounce. Google reports that the probability of a bounce from a page that loads in 3 seconds is 32%, compared with the 90% bounce rate of one that loads in 5 seconds.
With so much of your site’s success hinging on load times, page speed monitoring is non-negotiable. That way, when something causes a performance bottleneck that’s killing your on-page linger times, you get an instant alert that sets fixes in motion long before they can impact your broader user base.
Latency
When you conduct a ping test, you measure the network latency, which is how long it takes a user to receive the requested data packet. So, if the client device requests a data packet at 08:02:00.000 and the data center receives the request at 08:02:00.138, then the latency is 138 milliseconds.
Naturally, the lower the latency, the faster websites and applications are. It provides quicker feedback to the user and an overall more pleasant experience engaging with a digital service. According to Deloitte, latency is the number one driving factor behind high bounce rates on mobile sites.
If your latency is high, it’s a sign that something’s slowing down the data flow, whether it be the physical distance between the user and the server or a sudden surge of traffic eating up capacity. Any spikes in latency should be analyzed to determine how to get data moving through the network path again.
Bandwidth Utilization
IT teams monitor bandwidth utilization to determine how well the current servers meet users’ needs, expressed as a percentage of the total available capacity.
This utilization metric will vary over time depending on the traffic a web application experiences. DevOps teams should be prepared to scale as appropriate to ensure excellent website performance without wasting resources.
For example, let’s say that your bandwidth utilization consistently hovers in the 95%-99% region. That’s a sign that your network is just about at capacity, and there’s a good chance that users are experiencing slower speeds. At that point, it’s time to consider scalability options to serve users with the experience they expect.
Low bandwidth utilization won’t necessarily affect users but can affect your bottom line. If traffic needs are met by 40%-50% of the bandwidth, downgrade capacity to reduce costs.
Throughput
The easiest way to understand the relationship between the theoretical capacity of bandwidth and the concrete throughput data is by picturing a water pipe.
The total capacity of the pipe is the bandwidth, and throughput is the amount of water that flows through it within a given time frame. So, even if you have a wide pipe (high bandwidth), there can be blockages along the way that decrease the rate at which water can flow (low throughput).
If your website monitoring metrics indicate that throughput is a lot lower than the available bandwidth, it can point to issues with network congestion, load balancing, or any other number of bottlenecks that can hog resources.
Looking To Measure Your Most Important Availability and Uptime Metrics, Stats, and KPIs?
Master availability and uptime metrics when you try Uptime.com’s free monitoring and reporting tools! Our easy-to-use platform provides insights to help your team refine their service improvement strategy and comprehensive reports so you can track the data along the way.
Sign up for a free, 14-day trial to experience Uptime.com monitoring and take the first step toward building a more reliable, high-performance service.
Minute-by-minute Uptime checks.
Start your 14-day free trial with no credit card required at Uptime.com.


