Trusted by the world’s premier organizations
Our monitoring solutions provide unmatched visibility and availability, empowering engineering, operations and SRE teams to monitor & respond to their most essential services.
Stay ahead of downtime, keep your team informed and take action before customers even notice with real-time alerts via SMS, email, phone, and integrations like Slack and PagerDuty.

Our monitoring solutions provide unmatched visibility and availability, empowering engineering, operations and SRE teams to monitor & respond to their most essential services.
with every second of load time between 0-5 seconds.
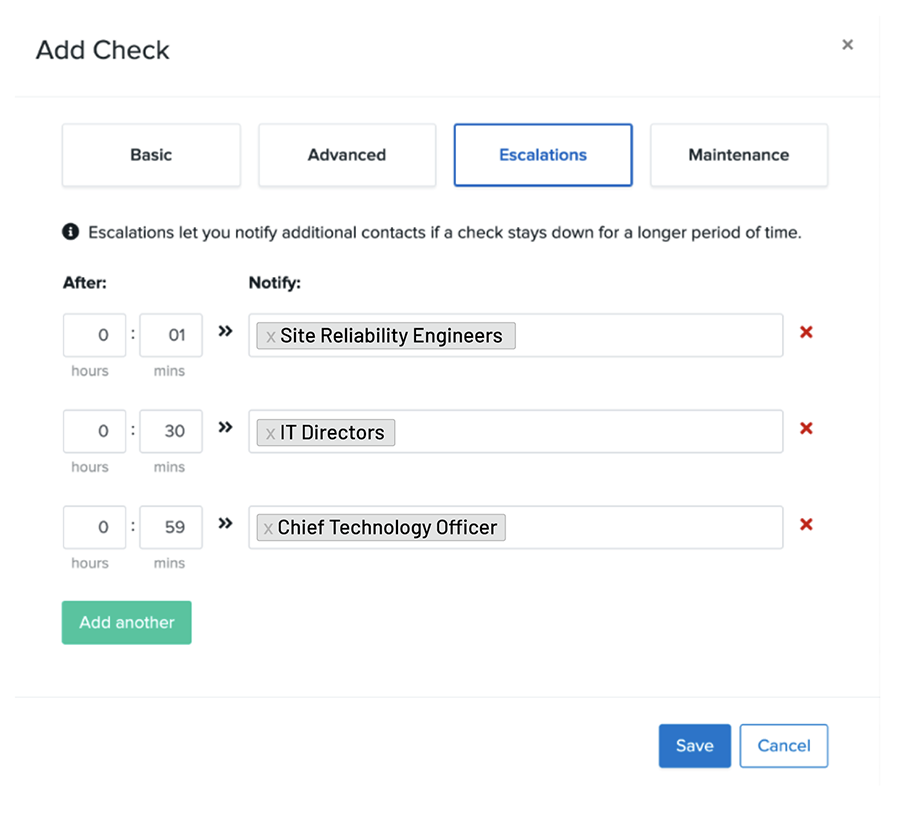
DOWNTIME ALERT ESCALATIONS
Customize alerts across call, text, email, and popular DevOps tools. Designate contacts and set escalations by severity or seniority levels.
MULTI-CHANNEL INCIDENT ALERTS
Get moment-it-happens web downtime and performance alerts to any device or software tool you use and prefer. If you're notified -- it's for good reason.

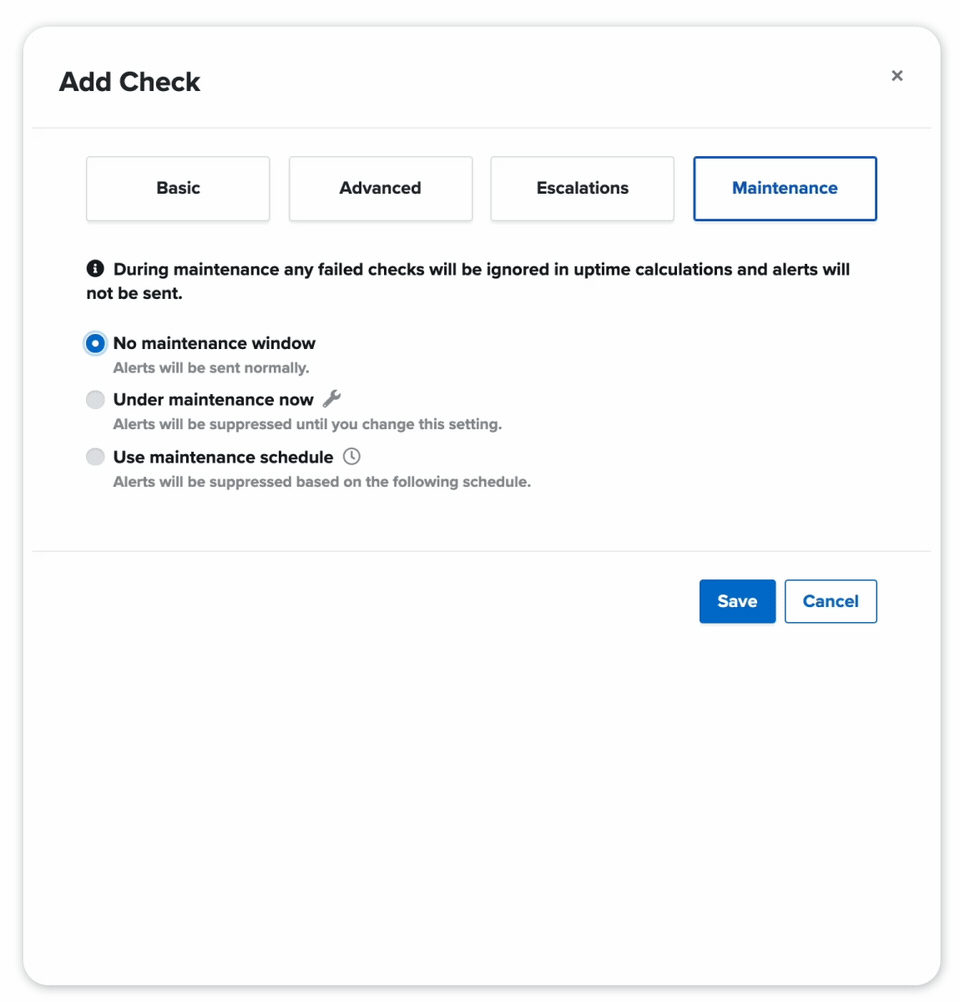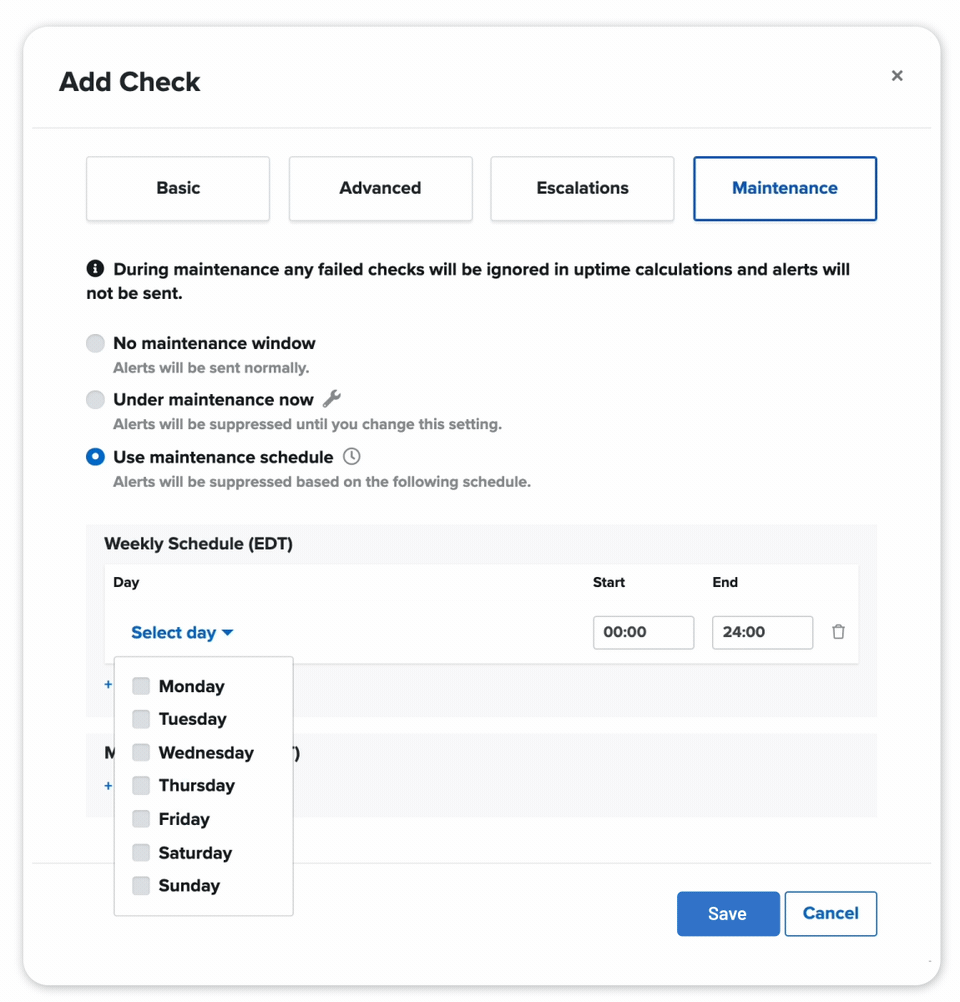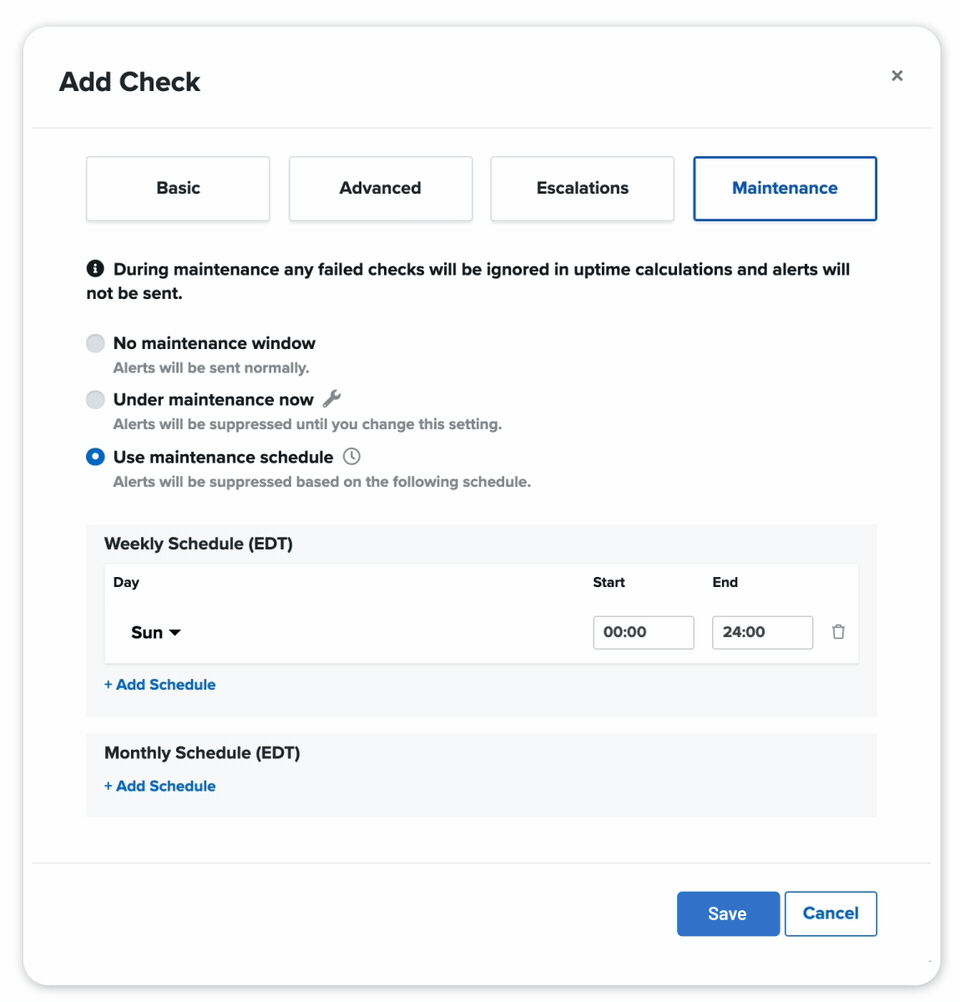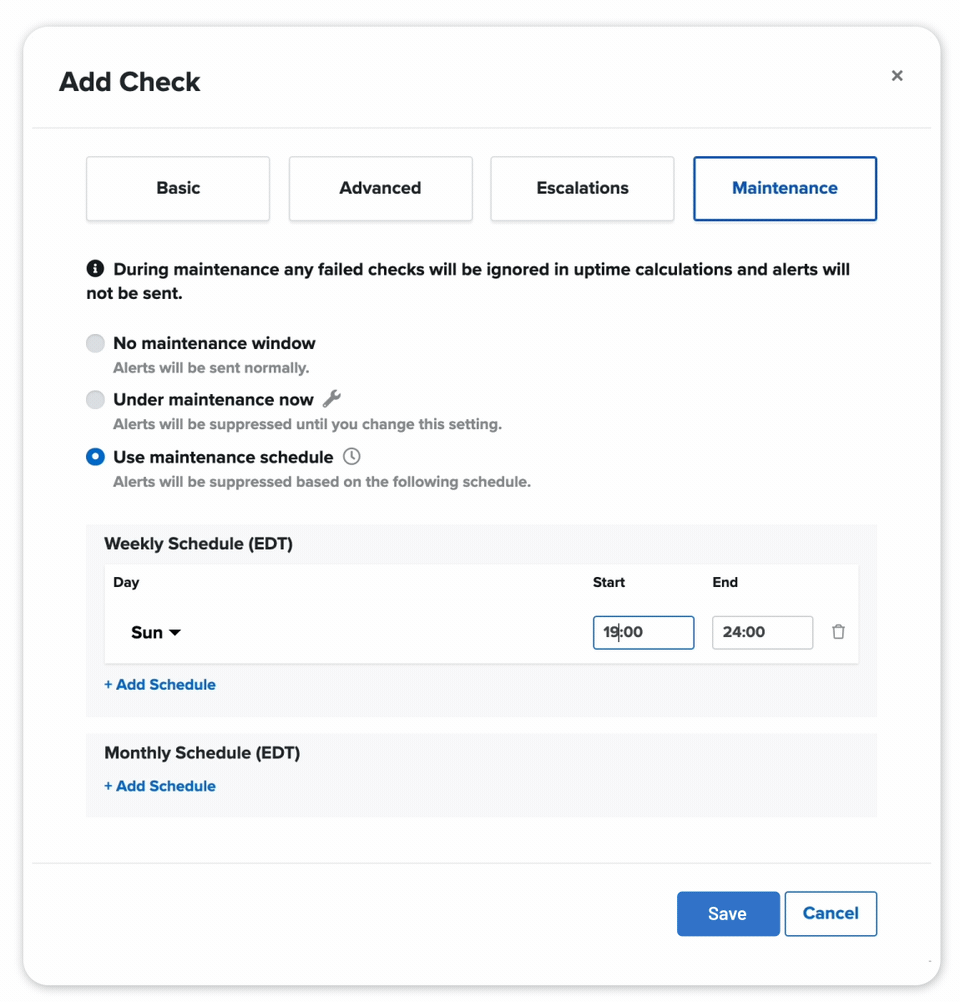
ACCURATE WEB MONITORING ALERTS
We double-check our web monitoring checks from multiple locations and won't alert you during designated windows to decrease false positives -- and increase a good night's sleep.
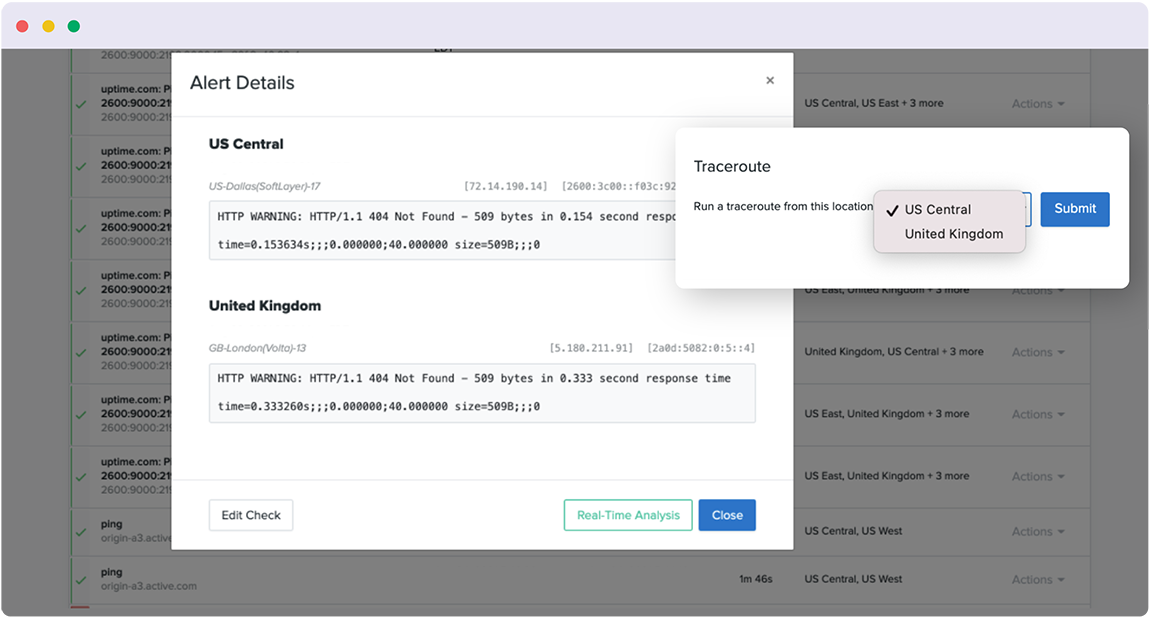
NETWORK TRACEROUTE DIAGNOSTICS
Efficiently detect downtime regionally, globally, and everywhere else. Get real-time check statuses to quickly delineate (and fix) local isolated incidents versus global outages.
GROUP WEB MONITORING ALERTS
Customize grouped monitoring checks with alert conditions. Easily structure alerts and escalations for teams and contacts. Learn more.
UPTIME MONITORING SUPPORT
Like our platform, our people are always up. Trust the industry's top-rated technical support team to quickly resolve website downtime and performance issues.

"Nothing to dislike: no false notifications"
"A reliable service which can be configured with great simplicity to monitor any kind of website. Its alert system is able to notify you and trace issues immediately."