





- Website Monitoring Service
- •
- Uptime Monitoring
- •
- API Monitoring
- •
- Page Speed Test
- •
- Status Page
The Industry's
Highest Rated
Website Monitoring,API Monitoring, Uptime Monitoring, Status Page, Page Speed Monitoring, Availability Monitoring
Service.
Uptime.com delivers a value-driven, comprehensive uptime monitoring platform that emphasizes speed, reliability and efficiency ensuring you can quickly identify, communicate and resolve outages with minimal downtime.
14-day free trial
No credit card required
24/7/365 real-time support
Resilient & secure platform
Trusted by the world’s premier organizations.
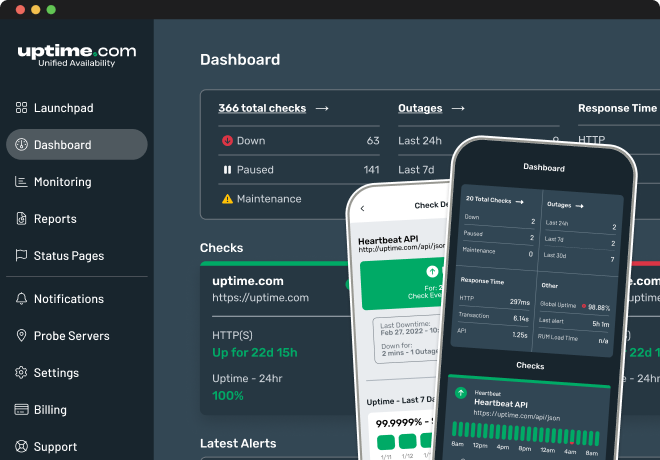
Our monitoring solutions provide unmatched visibility and availability, empowering engineering, operations and SRE teams to monitor & respond to their most essential services.
Everything you require for
unified availability monitoring
Simple & intuitive industry leading Enterprise-grade features delivered at a fair price, that are continuously improving.

Status Page
The all-in-one incident management platform to communicate updates to private and public audience.
Create a Status Page
API Monitoring
Effortlessly monitor APIs in real-time with our robust API monitoring solution. Ensure uptime, detect issues, and optimize performance.
API Checks
Real User Monitoring (RUM)
Gain insights, detect bottlenecks, and boost website performance to enhance user experience for your business.
RUM Checks
Website Monitoring
Configure sophisticated uptime monitoring checks without sacrificing simplicity. Detect downtime, optimize speed, and ensure a seamless user experience.
Website Checks
Private Location Monitoring
Get real-time data and statuses on private monitoring tests to detect anomalies impacting internal systems. Precise, confidential, and always in your control.
Private Location Checks
Synthetic Monitoring
Continuously test the availability, performance & functionality for all of your website's critical flows with real browser synthetics. Detect failures, boost website reliability by adding new checks within minutes.
Synthetic ChecksProven Platform. Reliability is our focus. Our users depend on the best.
But wait, there's more...
Share Incident Updates
Keep users & customers updated when an incident is resolved. Include a summary of the issue , impact to your business and the steps taken to resolve it.
Custom Status Pages
Provide real-time, up-to-the-minute status of incident updates, including any performance issues, scheduled maintenance and service disruptions.
Response Time Monitoring
Monitor response time and availability from locations around the world from public locations and private locations to enable complete visibility.
Maintenance Windows
Notify users about the date, time and expected impact of a system or service maintenance. Allow users to subscribe to maintenance notifications.
Private & Public Cloud Monitoring
Monitor services anywhere they are running. Deploy our Private Location monitor to enable visibility in Private Cloud or leverage our extensive Public Cloud Locations for complete visibility.
Worldwide Observability Network
Leverage the most reliable geographically distributed observability network to ensure granular visibility to where your customers reside and ensure your services are reachable everywhere.
Page Speed Monitoring
Configure a page speed check that run daily to ensure your sites perform well over time. Ensure your website loads fast for visitors worldwide, optimized for performance & customer experience.
Advanced Alerting
Get alerts anytime, anywhere. Our Advanced Alerting engine is highly tuned to eliminate false positives. Send alerts to multiple integrations to enable rapid response and resolution.
Dashboards
Customizable dashboards with critical uptime performance data needed for NOC visibility, continuous insights and realtime response to alerts and failures.
 Global Services Visibility
Global Services Visibility
Stay in control and gain full visibility across on-premise, cloud and hybrid infrastructures. Don't limit your monitoring visibility - ensure complete coverage worldwide!
View Our Global Network
-
Secure - We build trust with a secure monitoring management platform, always putting your data protection first.
-
Reliable - Don’t let unexpected web incidents leave your customers in the dark. We strive for reliability in everything we build and operate for your peace of mind.
 UPro! Services
UPro! Services
Considering Website Monitoring or any of our monitoring solutions but not sure where to start? Let us take care of the implementation, enabling you to focus on what matters most in your business.
Our expert team goes beyond simple setup; we provide detailed configurations, personalized training and robust support, ensuring you can fully leverage the Uptime.com platform.
Contact Us to Learn More
Start monitoring your website in seconds
14-days free trial
No credit card required
24/7/365 real-time support
Resilient & secure platform
Downtime is inevitable.
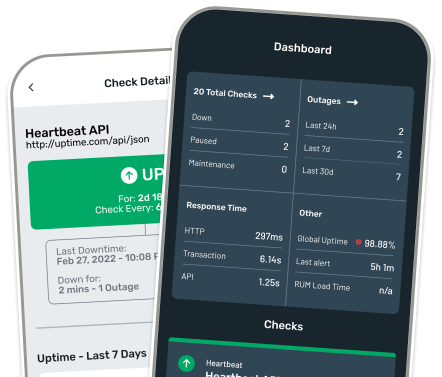
Receive alerts and respond on the go.
See all integrations









Be alerted while you're mobile.
Mobile-first incident management.
Get notified instantly to monitor uptime on the go.

Not just another monitoring service. We are invested in your success.






200+
Recommended by hundreds of verified users on;
G2, SourceForge and TrustPilot



80+ NPS
Consistently the highest Net Promoter Score of
any website monitoring provider in the market

24/7/365
Award-winning support team available
24/7/365 to proactively resolve issues

SOC 2 Type II
AICPA SOC 2 Type II audit completed, confirming
the highest standards of compliance

Consolidate & save with the most reliable
unified monitoring platform.

- Custom Status Pages
- Largest global observibilty network
- 3 minute checks
- Advanced API & Synthetic Checks
- 10 User Accounts
- 200k RUM page-views included
- Self-Service Add-ons
- Continuous Innovation
- Dedicated Customer Success Manager
$67/mo
vs

Statuspage
Hosted Status Pages
$250/mo
+

Pingdom
Uptime Monitoring - 3 users
$120/mo
$370/mo